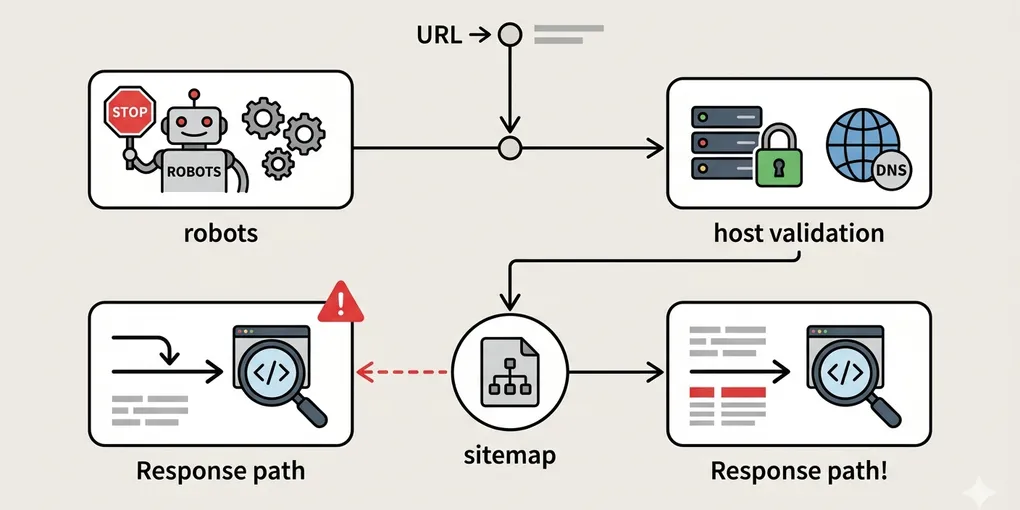
정적 사이트 sitemap could not be read를 점검하는 순서
“Sitemap could not be read”는 사이트맵 파일 자체 문제처럼 보이지만, 정적 사이트에서는 파일 안보다 파일 주변 한 단계가 더 자주 틀어진다. XML은 존재해도 live 응답, robots 규칙, redirect 경로, 호스트 설정이 어긋나 있으면 같은 오류가 난다.
그래서 가장 빠른 해결은 사이트맵 파일부터 고치는 게 아니다. live URL에서 읽을 수 있는 XML까지 가는 가장 짧은 경로를 먼저 확인하는 쪽이 빠르다.
1. live sitemap URL부터 연다
로컬 파일이나 build 산출물에서 시작하지 마라. 검색 도구가 실제로 가져가려는 공개 URL부터 열어야 한다.
첫 확인은 하나면 충분하다. 지금 이 live sitemap URL이 읽을 수 있는 XML을 반환하는가.
2. 파일 존재와 응답 정상 여부를 분리한다
정적 사이트에서는 이 둘이 같은 문제가 아니다. build output 안에는 파일이 있어도, live 라우트는 여전히 HTML fallback이나 redirect loop, 잘못된 호스트를 반환할 수 있다.
그래서 먼저 봐야 하는 것은 아래다.
- 최종 공개 URL이 무엇인가
- 실제 응답 상태 코드가 무엇인가
- 본문이 HTML이 아니라 XML인가
3. live 응답 다음에 robots.txt를 본다
사이트맵 URL이 살아 있는데도 검색 도구가 계속 실패를 말하면, 다음은 robots.txt다. 필요한 경로를 막고 있거나, 실제 호스트와 다른 sitemap URL을 노출하고 있을 수 있다.
이 단계에서 묻는 질문은 “robots가 있나?”가 아니다. “방금 확인한 sitemap URL과 robots가 같은 경로를 가리키나?”다.
4. 최종 호스트와 redirect 경로를 같이 본다
정적 사이트에서 자주 나는 실패는 하나다. 제출한 sitemap URL, canonical host, 실제 배포 호스트, robots host가 서로 안 맞는 경우다.
이 네 가지를 같이 확인한다.
- 제출한 sitemap URL
- 실제로 XML을 내주는 호스트
- 중간 redirect가 있는가
- robots.txt가 가리키는 호스트
이것들이 안 맞으면 사이트맵 파일은 멀쩡해 보여도 fetch는 계속 실패한다.
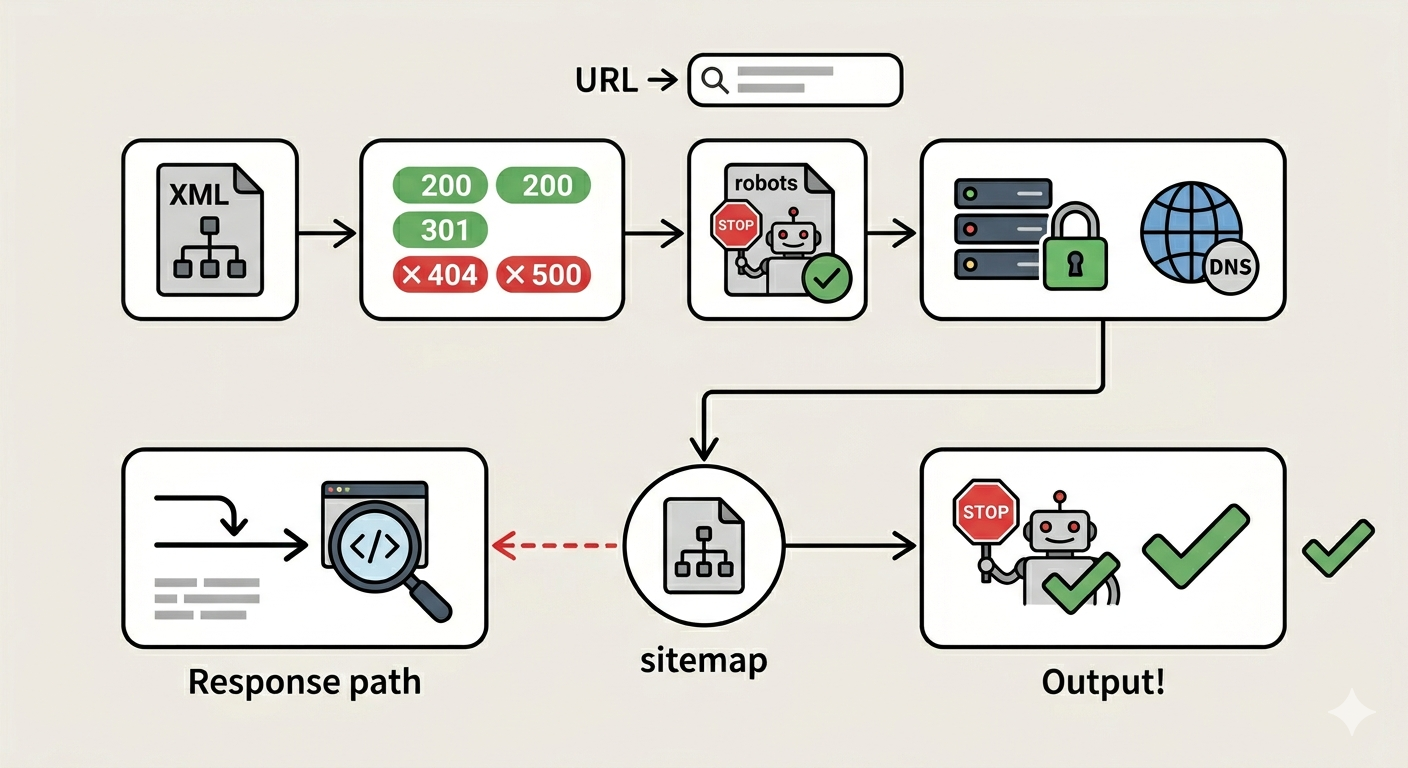
5. 점검 순서를 짧게 고정한다
짧은 순서 하나만 고정해도 충분하다.
- live sitemap URL을 연다
- XML 본문과 상태 코드를 확인한다
- robots.txt를 본다
- 최종 호스트 일치 여부를 확인한다
- 그다음에만 sitemap 파일 내용을 본다
이 순서가 중요한 이유는, 정적 사이트 sitemap 실패의 대부분이 파일 내용 문제보다 라우팅 문제에서 먼저 시작되기 때문이다.
무엇부터 시작할까
파일을 고치기 전에 먼저 live sitemap URL의 정확한 응답부터 확인해라. 공개 호스트에서 XML이 깨끗하게 안 보이면, 사이트맵 내용만 수정해서는 실제 문제를 못 고친다.