
How to run robots.txt safely on a static site
On a static site, robots.txt is small enough to feel harmless. That is exactly why it causes expensive mistakes. One bad block can hide your entire content set from search or stop useful assets from being crawled.
Use the static website operations unit page as the index for follow-up posts on indexing, assets, domains, and deployment checks.
1. Robots is a crawl rule, not a privacy rule
The first thing to lock is the purpose. Robots.txt tells crawlers what not to request. It does not protect private content by itself.
2. Block less than you think
Many sites block folders because they look technical. That is often wrong. Templates, assets, locale paths, or generated pages can disappear from search workflows if you block too broadly.
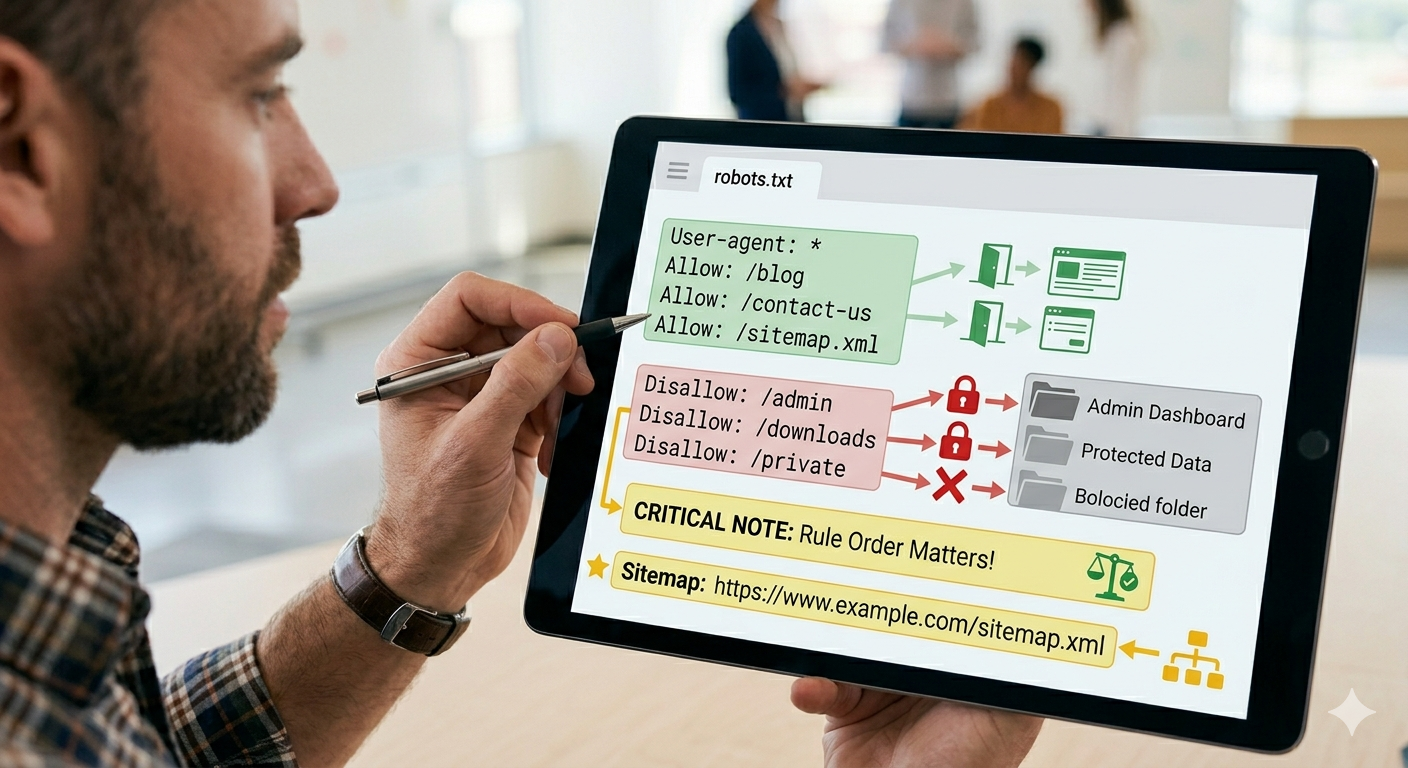
3. Always keep the sitemap reference
If you rely on search discovery, the sitemap line should be treated as part of your baseline. It belongs in the file and it should point to the live sitemap URL.
User-agent: *
Allow: /
Sitemap: https://example.com/sitemap.xml4. Verify the live file, not the local guess
In static operations, a correct local file does not matter if the deployed host is serving something else. Always open the live robots URL after deployment.
What to do first
Review your current robots.txt with one question: is it blocking anything that search still needs to crawl? If the answer is unclear, your rule set is too loose to trust.